概述
支持的模型
使用流程
一、创建批量推理任务
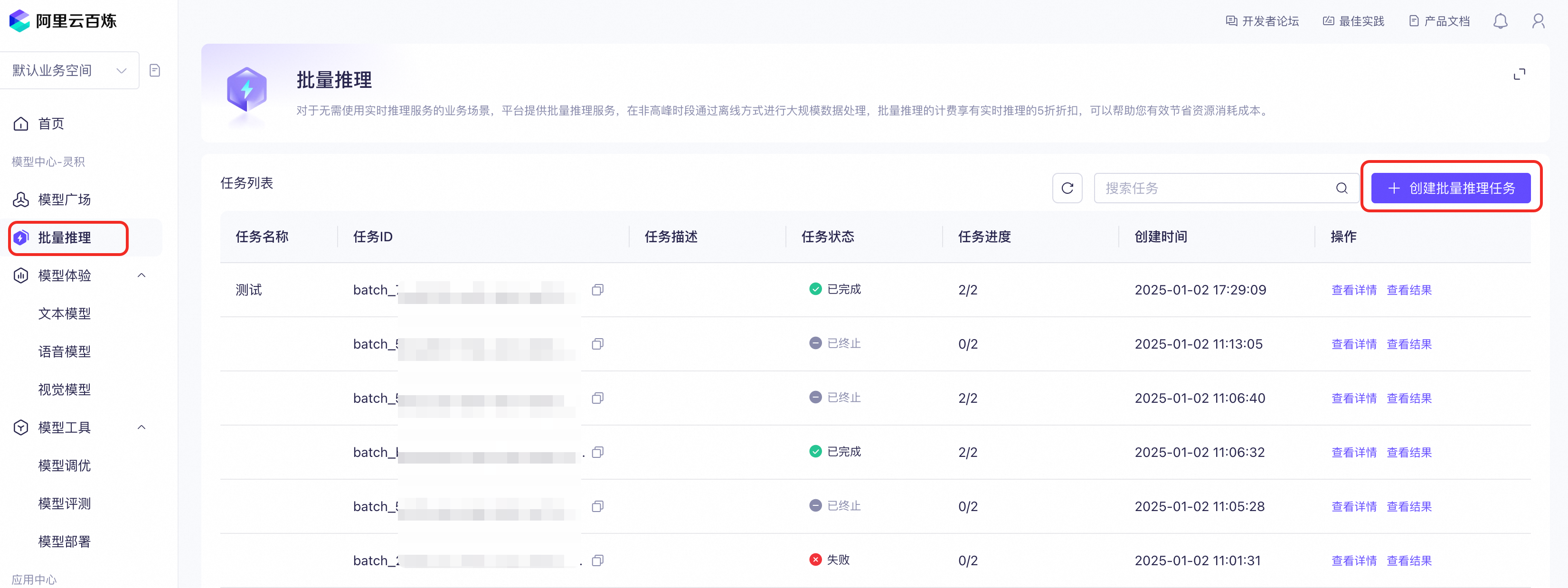
| 批量推理任务表页面 | 页面字段填写说明 |
|---|---|
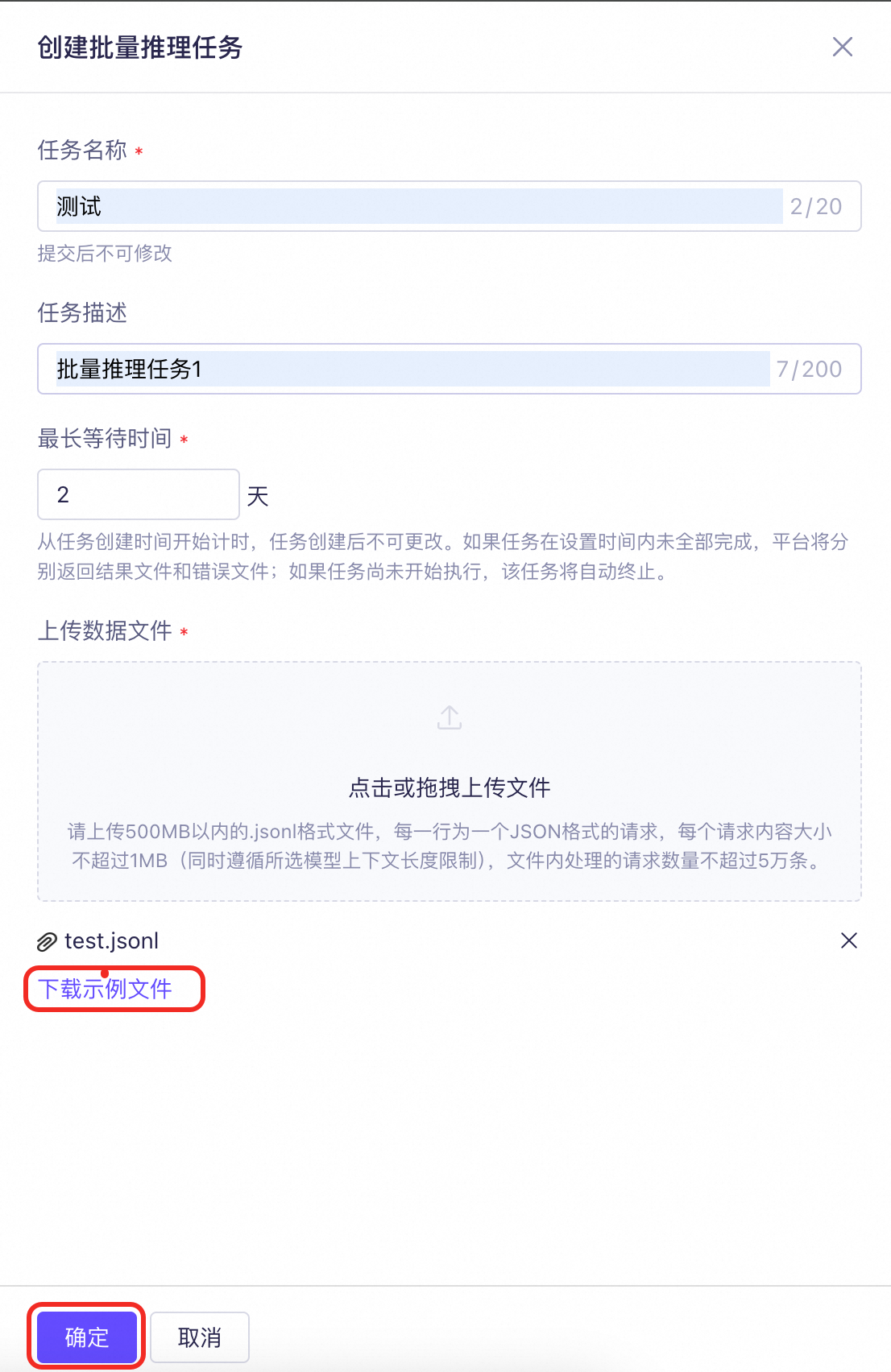 | 上传数据文件上传包含请求信息的数据文件。仅支持选择单个文件上传。请确保文件符合格式要求,可单击下载示例文件获取示例文件,参考文件格式。请确保文件中每一行数据的内容及格式正确,否则文件解析错误将影响任务执行;同一个文件内的数据行仅能请求一个模型,若存在多个模型,将导致文件解析错误。您也可以通过一些格式转换工具或脚本将您的请求文件转换成符合格式要求的JSONL数据文件。参阅CSV文件转换为JSONL文件。 |
二、查看与管理批量推理任务
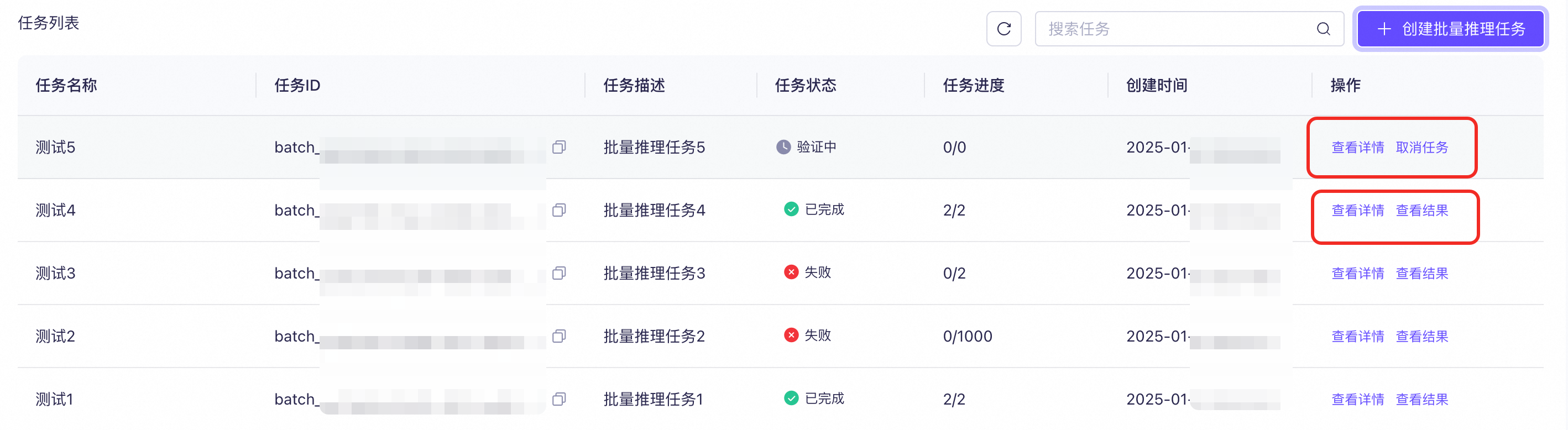
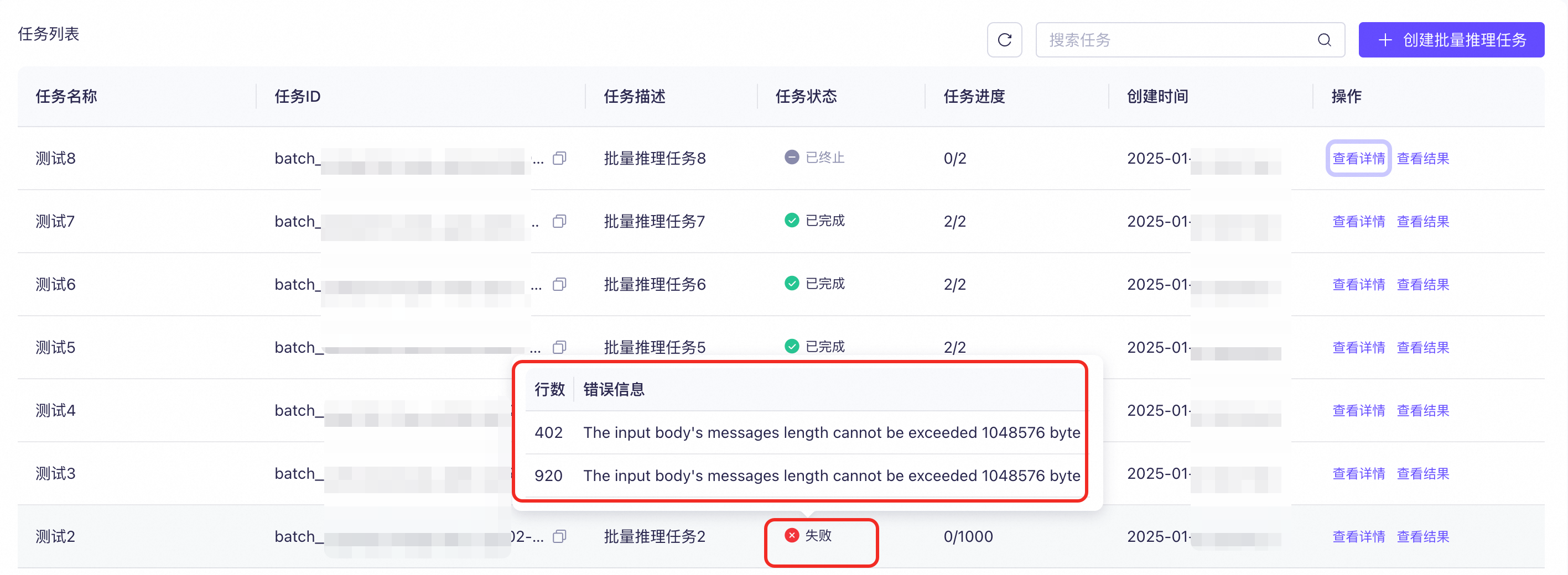
三、下载结果文件
失败状态,表示文件解析失败,无结果文件和错误文件输出,通过鼠标悬浮在任务状态文字上显示的错误信息检查上传的数据文件。
API调用
数据统计


计费
系统仅对批量推理任务中已经执行成功的请求进行计量计费,未执行的请求不计费。
修改于 2026-05-27 12:38:35